LLM Models for Agentic Workflows
LLM Models for Agentic Workflows
Autonomous Coding Agents: For code generation/refactoring tasks, prefer code-specialized open models. Meta’s Code Llama family (7B, 13B, 34B params) is state-of-art for coding tasks and is free for research/commercial use. Alibaba’s Qwen2.5-Coder models (0.5B–32B) are fully open and achieve SOTA code performance (the 32B variant rivals GPT‑4o). BigCode’s StarCoder (15B) is another open code LLM trained on GitHub (80+ languages) that outperforms prior open-code models. Smaller open models (e.g. GPT‑J, CodeGen) can work for lightweight tasks. For extreme efficiency, Microsoft’s new Phi-3 family (3.8B, 7B, 14B) offers high-quality output on standard benchmarks, outperforming larger models of similar size.
Autonomous Research Agents: Agents that do literature review or information synthesis benefit from high-capacity general LLMs with long-context support. Meta’s latest Llama 3.1 (available 8B, 70B, 405B) and Mistral Large 2 (7B, 13B) both support very large context windows (up to 128K tokens) and match or exceed GPT‑4 performance on many tasks. Microsoft’s Phi-3 models (mini, small, medium) are also very efficient for NLP and coding tasks. For specialized knowledge retrieval, one might use a base model (Llama/Mistral) plus retrieval, or smaller turbo versions (e.g. Llama 2-chat 7B) with a strong retriever.
Collaborative Multi-Agent Teams: In multi-agent scenarios, you can mix and match models by role. For example, a “researcher” agent might use Llama 3 or Mistral for broad knowledge, while a “coder” agent uses Code Llama or Qwen-Coder. In practice, choosing models depends on compute: on 16–24 GB GPU, models ≤14B (Llama 3-13B, Mistral-7B, Phi-3-7B) are safe bets. Very large models (70B+) need model parallelism or offloading. Table below compares some open models:
| Model | Size(s) | Best for | Notes |
|---|---|---|---|
| Llama 3.1 | 8B, 70B (and 405B) | General/NLP, coding (base) | Open, multi-modal features (images), 128K context. |
| Code Llama | 7B, 13B, 34B | Code generation, assistants | Trained on 500B code tokens; state-of-art coding performance. |
| Qwen2.5‑Coder | 0.5B, 3B, 7B, 14B, 32B | Code generation, refactoring | Fully open source; SOTA on code benchmarks (32B ~ GPT-4o). |
| StarCoder (BigCode) | 15B | Code generation, debugging | Permissively licensed; 80+ languages; >8000 token context. |
| Mistral Large 2 | 7B, 13B | General NLP, coding | Highly efficient; 128K context; top benchmark scores. |
| Phi-3 family | 3.8B (mini), 7B, 14B | General NLP, coding | Small, optimized; outperforms larger models of same size. |
| LlamaIndex (GPT Index) | N/A (framework) | RAG pipeline builders | Tools for indexing and retrieval over domain docs. |
Orchestration Frameworks
LangChain / LangGraph: LangChain (Python) provides agents, chains, and memory abstractions. Its new LangGraph library models multi-agent systems as nodes and edges: each node is an agent with its own prompt, LLM, and tools, and edges define communication/control flow. LangChain is fully open-source and has many integrations (OpenAI, HuggingFace, Ollama local models). LangChain’s Agents and Tools paradigm makes it easy to plug in a calculator, browser, or code executor.
Haystack (deepset): An end-to-end LLM framework for RAG and agents. It provides Pipelines and new “Swarm” primitives for multi-agent workflows. Haystack’s Swarm (inspired by OpenAI’s "Swarm") uses function/tool calls to let agents hand off to each other. For example, you can define routines and handoffs between LLM-driven agents so one agent’s output becomes another’s input. Haystack supports integrations with OpenAI, Anthropic, or local models (via Ollama). Its DocumentStores (FAISS, Milvus, Elastic) serve RAG retrieval, and it has a simple memory component for conversation state.
CrewAI: An open-source Python framework (MIT-licensed) for building teams of agents. CrewAI introduces the concepts of Crews (teams), Agents (with roles/skills/tools), Processes (defined workflows), and Tasks. CrewAI is designed for structured, team-based automation: each agent has a role and skillset, and processes manage how tasks flow between agents. It is highly customizable (low-level APIs available) but offers “out of the box” orchestration for parallel agents and sequential flows. CrewAI is model-agnostic: it works with OpenAI or any open LLM (via connectors). In practice, CrewAI excels when the overall workflow is well-defined (e.g. copywriting + editing team).
AutoGen / AG2: Microsoft's open-source framework (MIT license) for multi-agent applications. AutoGen (recently rebranded AG2) focuses on flexibility for open-ended tasks. It supports AgentChat for building individual agents and Teams for collaborative tasks. AutoGen’s GraphFlow lets you compose complex workflows of agents. It has built-in support for memory/RAG (e.g. a Memory interface to query and update knowledge stores). Like CrewAI, it’s written in Python. AutoGen tends to assume agents may solve subproblems iteratively, so it gives fine-grained control, whereas CrewAI is more prescriptive. (An industry comparison notes: “CrewAI...is great for structured, known workflows; AutoGen for open-ended, exploratory tasks”.)
LangChain vs. Others: In summary, LangChain is the de facto open-source library for chain-of-tool agents and has broad support/memory features. Haystack is strongest on RAG search and educational multi-agent patterns (Swarm). CrewAI and AutoGen are new agent-team frameworks: CrewAI offers quick setup and role-based teams, while AutoGen offers deep customization and experimentation (graph-based workflows, custom policies, etc.). All are under active development; they can interoperate (e.g. a CrewAI agent could use LangChain Tools internally).
Memory, Vector Databases, and RAG Strategies
Memory for Agents: Agentic systems often need both short-term (conversation) and long-term (knowledge/memory) context. A common pattern is Retrieval-Augmented Generation (RAG): when an agent receives a query, it retrieves relevant facts from a knowledge store (vector database or document store) and adds them to the model’s prompt context. AutoGen’s docs outline a memory protocol (methods like query, update_context) to implement this. Agent frameworks (LangChain, Haystack, AutoGen) include simple memory backends (key-value or text-history) and allow plugging in a real vector DB.
Vector DBs (long-term memory): Popular open-source vector databases include FAISS (C++/Python library by Meta), Chroma (Python, easy to use), Qdrant (Rust, local or cloud), Weaviate (Go), and Milvus. All can run on a single server. For extremely lightweight needs, SQLite with vector search extensions (e.g. SQLite-Vec) lets you store embeddings in a file. For example, LangChain highlights SQLite-Vec – an SQLite extension for vector search – which “does not require any credentials” and operates entirely via a local SQLite file. This can be a good fallback instead of deploying a separate DB server.
In each case, you’d use an embedding model (e.g. SentenceTransformers) to index and query passages. At runtime, the agent constructs an embedding of the query (or context), retrieves the top-N similar docs from the vector store, and inserts those snippets into the LLM prompt. This RAG loop extends the effective context window. For on-the-fly memory (e.g. remembering recent user inputs), a simple in-memory buffer can suffice. For larger-scale, frameworks like Mem0 provide hierarchical memory layers for AI agents.
Lightweight vs. Heavy Solutions: When resources are limited, choose simpler storage. SQLite (with or without vector extension) or HDF5/Parquet files can hold small knowledge graphs or embeddings. Even a JSON/CSV log of past interactions can be parsed when needed. Full-scale vector DBs (which may require running a Docker container and 2–4GB RAM) are heavy but offer indexing performance. For truly minimal setups, an in-memory list of embeddings (using FAISS’s Python index or even brute-force NumPy search) may work if data is small.
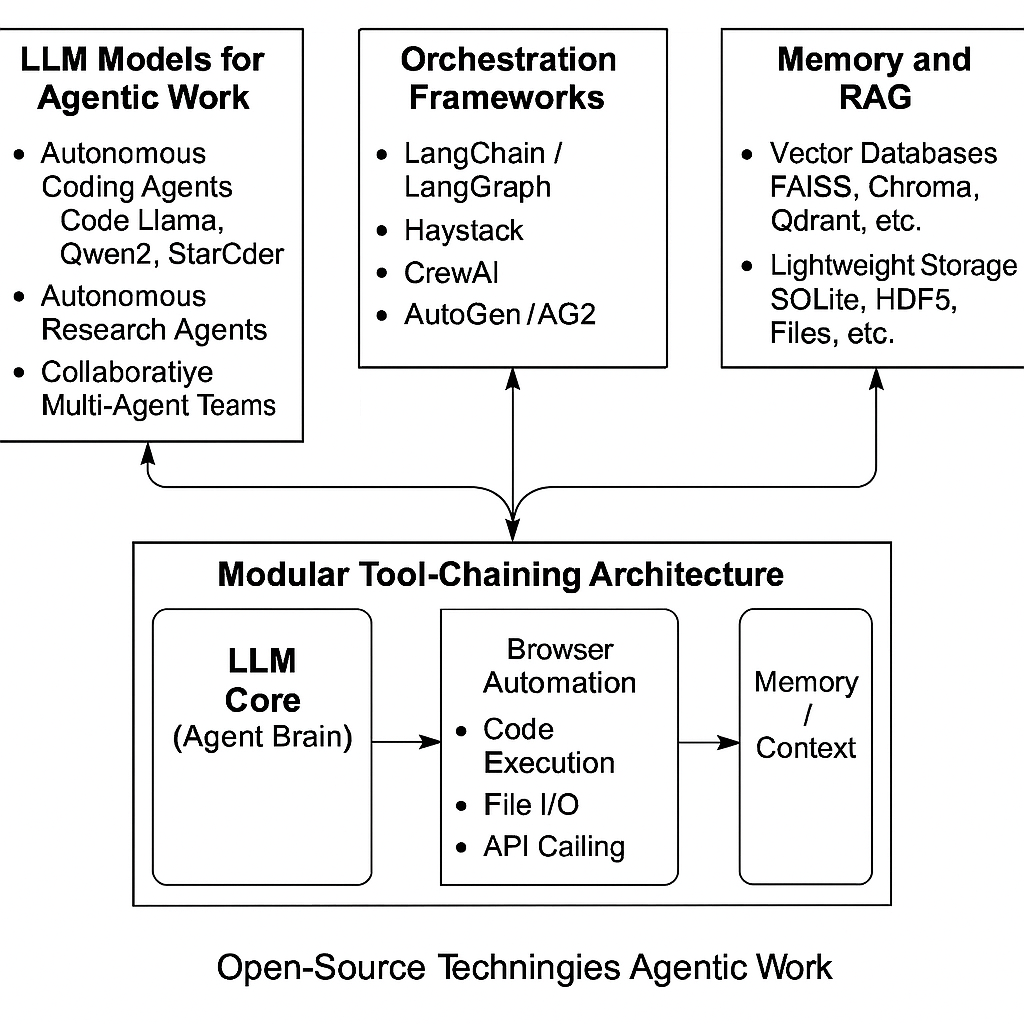
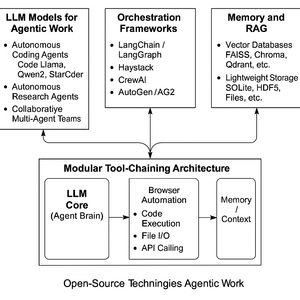
Modular Tool-Chaining Architecture
Agentic workflows rely on chaining various tools. A modular architecture typically has: (1) an LLM core (as an “agent brain”), (2) tools (external actions the agent can invoke), and (3) memory/context as described. Common tools include:
Browser Automation: Web-scraping or UI automation can be done with libraries like Selenium, Playwright, or via headless Chrome (e.g. pyppeteer). Agent frameworks often include a “web browser” tool. Haystack, LangChain and AutoGen have examples for calling a search engine or clicking links.
Code Execution: Many coding agents must run or test code. Tools include a Python REPL (e.g. using
exec()), Dockerized sandboxes (like E2B or function-call-as-service), or Jupyter integration. For security, you may isolate this (E2B’s sandbox runs each snippet in a micro VM).File I/O: Reading/writing files is usually done with built-in Python (
open()). Some frameworks let the LLM directly query a “filesystem” or plugin (e.g. LangChain’sFileTool).Terminal Control: Agents might run shell commands. This can be handled via Python’s
subprocessor libraries like pexpect. In VSCode-based agents (like Cline) or Goose, the agent can issue git, pip, or other CLI commands.API Calling: REST or RPC calls to external services. The agent calls e.g.
requests.get()or uses a specialized wrapper (LangChain has HTTP tool, AutoGen has web-surfer extension). This lets agents query search APIs, call knowledge bases, or use task-specific services.
In practice, you encapsulate each tool behind a well-defined interface (often via function calling or JSON I/O). For example, LangChain’s Tool class or AutoGen’s Function Calling system. Each agent is given a set of tools it can call by name with arguments. When the LLM outputs a function call, the orchestrator executes that tool and returns the result to the LLM to continue reasoning.
A typical modular pipeline might look like: User Query → (Orchestrator) → Agent prompt with tools → LLM generates action → Tool execution (e.g. search or code-run) → Memory update/RAG retrieval → Next prompt to LLM. Tools are stateless bridges to external actions, keeping the agent architecture clean. This separation means you can swap out components (e.g. replace Selenium with a ChatGPT-function call to a browser, or use a different vector DB) without rewiring the agent logic.
Scheduling and Multi-Agent Coordination
For multi-agent teams, scheduling and task allocation is key. Approaches include:
Central Orchestrator: A manager node routes tasks. For example, CrewAI’s Process defines how tasks are assigned to agents and in what order. LangChain’s LangGraph can be used to control flows (edges trigger agent calls). AutoGen’s GraphFlow similarly orchestrates agent execution. In these designs, one piece of code or a master agent monitors state and invokes sub-agent jobs in sequence or in parallel.
Asynchronous/Event-driven: Use a message queue or async framework. Agents can run concurrently (e.g. use Python’s
asyncio, or Ray Actors). AutoGen’s recent updates include concurrent GraphFlow execution. You can also use Celery/RabbitMQ or Redis Streams to dispatch tasks between agents. Each agent listens for tasks of its type. Care must be taken to avoid race conditions in shared memory; often use transactional DB writes or locked queues.Role-based loops: Define a conversation protocol. For example, Agent A does a search and sends results to Agent B to process, then back to A, etc. This can be implemented with simple loops:
while not done: agent1.do(); agent2.do(). Tools like LangGraph naturally express this as edges in a graph, and frameworks can handle turn-taking (handoffs in Haystack Swarm).Scheduling Policy: For efficiency, consider agent priorities and compute limits. For example, give lighter tasks to small models and only invoke big models for summaries. If GPUs are limited, you might time-slice: run one agent at a time. Memory sharing (vector DB) can serve multiple agents. Logging frameworks (LangChain’s LangTrace, CrewAI’s telemetry) help audit which agents run.
RPA-style Automation: If the agents must interact with software (like clicking UIs or filling forms), you can integrate an RPA tool. Open-source RPA frameworks (e.g. TagUI) can be called from Python. The orchestrator might translate an agent’s directive (e.g. “login to email, download report”) into TagUI scripts or use Playwright for browser automation.
Tabular Comparison of Key Frameworks:
| Feature/Framework | LangChain (LangGraph) | Haystack | CrewAI | AutoGen (AG2) |
|---|---|---|---|---|
| Agent Model | Chains of prompts + tools; graph flows possible | Pipelines & “Swarm” routines | Crews (teams), agents with roles | Agents and Teams; customizable workflows |
| Multi-Agent Support | Yes (LangGraph) | Yes (Swarm concept) | Yes (explicit Crews) | Yes (Teams, group chat) |
| Tools/Plugins | Large ecosystem (tools, models, memory) | Document store + tool nodes | Custom tools via methods; low-level API | Can wrap any function; supports function calling |
| Memory Integration | Built-in memories (buffer, index), use vectorstores | Pipelines often include retrievers (RAG) | No built-in long-term memory (use external DB) | Built-in Memory protocol for RAG |
| Ease of Use | Moderate (lots of features) | Moderate (focus on retrieval) | Easy (Pythonic, high-level) | Steeper (lots of abstraction) |
| Open-Source | Yes (MIT) | Yes (Apache) | Yes (MIT) | Yes (MIT) |
Overall, these frameworks can be combined. For example, one might use LangChain tools inside a CrewAI agent, or use Haystack’s document retrieval as the “brain” behind an AutoGen agent’s memory. The guiding principle is modularity: each agent or tool should do one thing (search, compute, write code, etc.), and the orchestrator/wrapper manages data flow.
Recommendations: For a local single-GPU environment, use smaller models (≤14B) and in-memory or file-backed DBs. Prefetch common data (knowledge bases) with a lightweight scraper (e.g. Firecrawl for web data) into your vector store. Use asynchronous calls where possible to keep the GPU busy (e.g. have one agent generate text while another embeds or searches). Profile each agent’s runtime: you may decide to run some agents on CPU (e.g. simple retrieval) while reserving GPU only for heavy LLM calls.
By leveraging these open-source LLMs and frameworks, one can build sophisticated AI agents that research, code, and orchestrate tasks autonomously, all within the constraints of local compute and without proprietary APIs.
Sources: We have drawn on public docs, blogs, and papers from Meta, Microsoft, Alibaba, and major open-source projects, ensuring recommendations are grounded in the latest available information.




Comments